

For those who follow me, you already know that to build a continuous testing suites that scales, and that lasts for more than few software iterations, teams must follow rigorous processes.
When i say teams – I mean developers, test engineers and business testers.
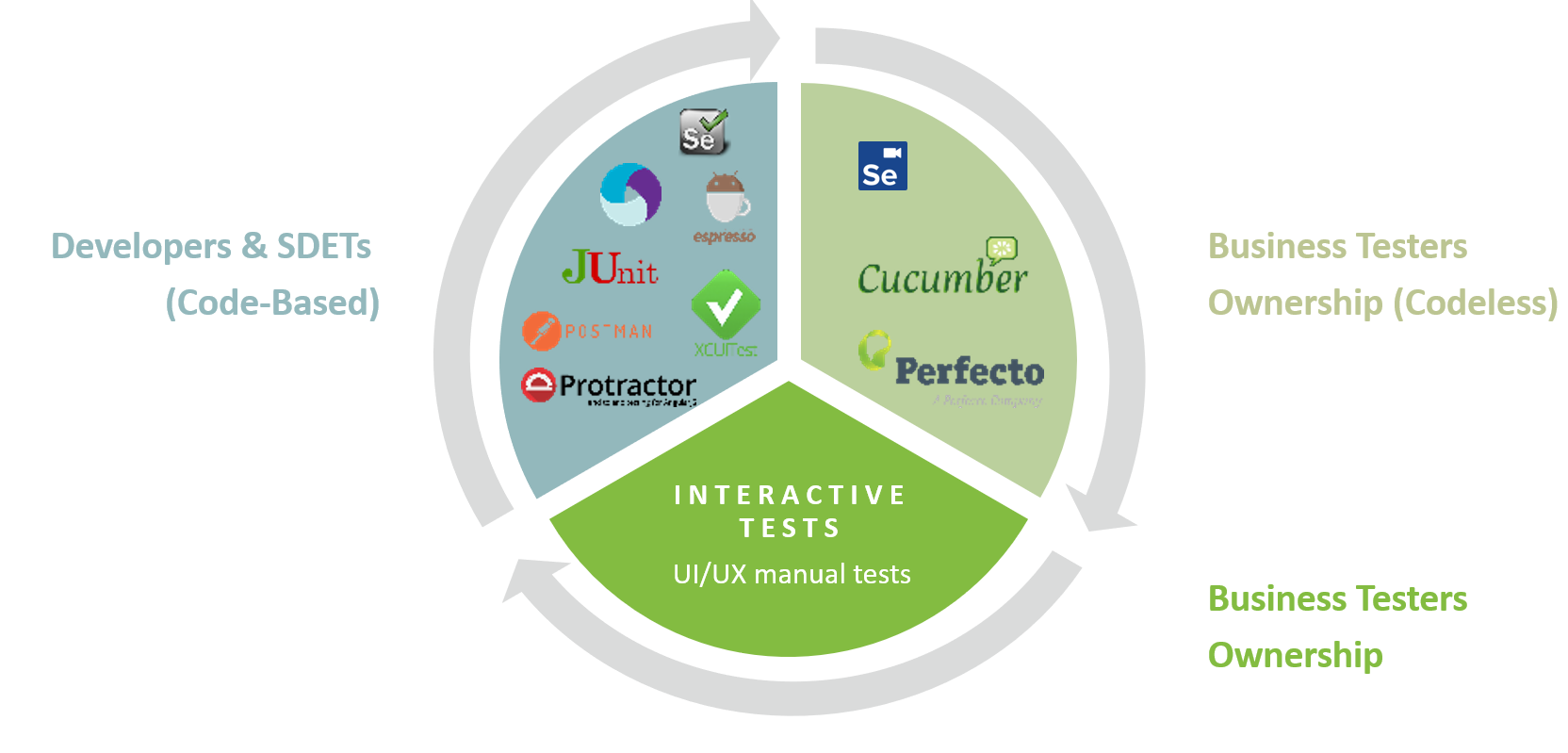
This post isn’t about balancing the work load between personas, but rather on continuously sharpening the test suites value to the entire team.
As we close a decade and enter a new one, and with some cool advancements in the technologies that include AI/ML but also challenging platforms like PWAs, Foldables, 5G and IOT – it’s the perfect time to re-evaluate our testing management and maintenance processes.
What Causes Test Instabilities?
Especially across the digital landscape, there are quite a few recurring patterns that causes test instabilities or flakiness.
- There are the scripts and frameworks that we use – in this category we can list object locators strategy, popups (security, system), coding skills, timing and steps synchronizations and more.
- There are backend issues around services, networking and up to date test data and environments.
- Lab related issues that includes platforms being unavailable or poorly setup for testing (screen is locked, network is disconnected, app isn’t installed, device isn’t in ready state mode)
- Lastly, Orchestration – This is a tricky root cause since there are not that many early warnings to these kind of issues up until you execute and scale up. Not having sufficient platform to test against, or knowing that a platform is in use is often hard to find (but – not impossible :))

In addition to the above 4 major categories, there are also of course the software development dynamics that includes advancements in the product, market changes that impact your test scripts and infrastructure, and also the external dependencies that you cannot always control (network carriers, 3rd party services that you depend on, etc.).
Test Automation Certification for Value vs. ROI
While there is no 100% safety net for the above mentioned RCAs (root cause analysis), but there are few steps that teams can take and enforce to minimize the risks.
My few recommended tips that should be examined every 2-3 software releases/iterations are:
- Think with the end in mind when you write a test automation script. Will the test provide value more than just once? Which test suites/types such test will fit (regression, functional, unit, etc.)
- Consider the maintainability of such test script over time, how difficult will that be? and will it be worth the hassle?
- Certify the test script prior to integrating it into any pipeline. Certification should address the stability of the test across multiple platforms (only works on my machine is not an option), test execution duration (Less than 5 minutes please), If it is a test that detected defects it needs to be scored somehow as a higher value test that others.
- Monitor and measure the impact of your test suites and correct not longer than once a quarter!
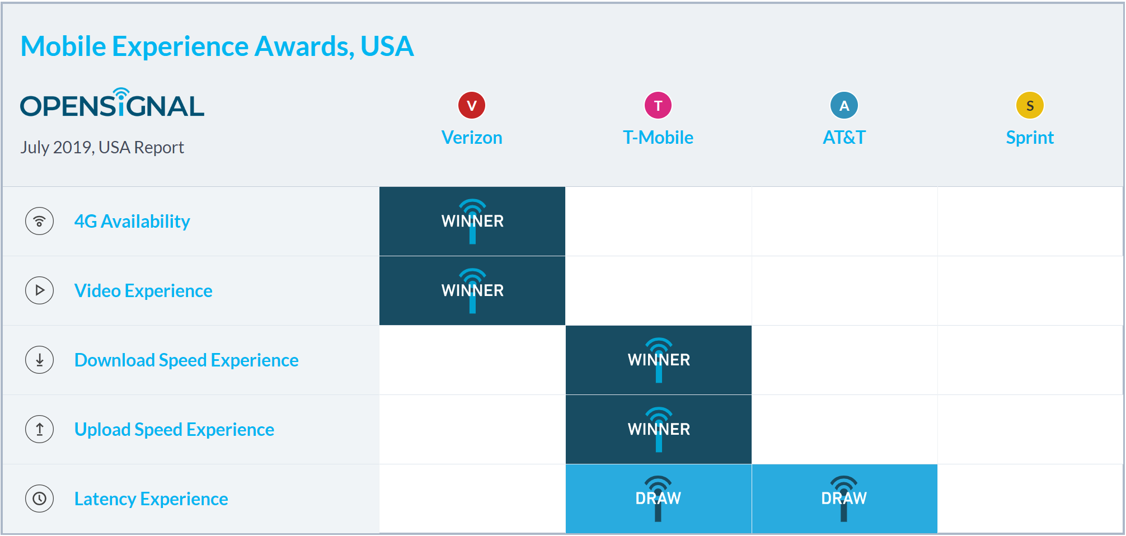
The above image is an example of an external dependency that can impact the performance of your app. Assuming you test your mobile app against real cellular networks, you should acknowledge that not every carrier behave and performs the same, and it may impact your overall results. Knowing, measuring and taking this into account can save false negatives and other wrong speculations.
Lastly, and as this section implies – it is time we stop measuring test automation ROI and $ but clear value and risk mitigation to the business. Test automation value is by far more wide than the legacy ROI metrics that were simply covering for cost of test creation and execution regardless of what the test executions actually results in.
I have recently delivered a session about test automation stability for the OnlineTestConf. You can view the recording and slides here
Power Of Analytics
While a lot of the above might be clear to many practitioners, what i often see in the market is that the time element prevents teams from actually seeing what’s wring with their testing infrastructures. Teams invest a lot of money, resources and of course time into building a cool set of testing suites, however once their done, the auto pilot steps in, and until something is broken, these suites remains blind spots. This is again, a legacy practice, and in the modern DevOps/Agile/Continuous Testing era, teams ought to monitor and gain maximum visibility into their test code continuously!

As the above visual suggest – only when you look into the reports in a smart way, you can improve quality, deliver fast and up to date feedback and Yes – get some ROI (in a form of value) from your investment.
Imagine you can upon demand answer questions like –
- what are my most problematic test scenarios?
- what are my most flaky or buggy platforms (mobile/web)?
- which job within my CI is the longest?
- Which test cases must be retired or be placed in a “blocked” bucket for maintenance (due to popups, objects, other)?
Knowing the above answers upon and perhaps prior to clicking on the RUN button could be a major productivity boost to your entire cycle, wouldn’t it?
The below are 2 real life example from the Perfecto tool, but you can think about similar implementation as well – In the below, based on AI and smart algorithms the tool scans the test reports for pre-defined patterns like popups, elements not found, platforms in use and others, but also allows teams to customize these and add unique and relevant RCAs on their own to better slice and dice the test data.


Bottom Line
As we wrap a decade of software development and testing, it’s perhaps time that we take our test automation a level up and inject smart algorithms, processes and more so we are always on top of what we build, and improve whenever there is a need.
Happy Testing!
